Building a DSL Runtime for Voice AI Agents
One thing that I have been thinking a lot about while working on voice agents is that most of the difficulty is not in writing code, the difficulty is in keeping the entire shape of the agent inside your head. A voice agent is not just a prompt and not just a graph and not just a bunch of function calls. It is all of these things together and then the user speaks something weird, STT mangles it, the LLM calls the wrong tool, the TTS has to say the right thing in the right language, the telephony provider closes the websocket and now you have to debug which exact layer broke. This is the real thing.
In the earlier spring-agent repository we had a very straightforward way of building flows. Every client flow had a python file with many create_*_node functions and each function returned the pipecat node dictionary. This worked extremely well in the beginning because it lets you build fast. You can just open python, create a node, add a prompt, add some functions, write a handler and move on.
But then the number of flows started increasing and the same pattern which helped us move fast started becoming the thing which was slowing us down. Every small change was now a code change. A prompt change was a python diff. A phase change was a python diff. A graph change was a python diff. The function schema which the model sees was inside python. The handler which actually performs the side effect was also inside python. The language phrases were sometimes inside python. So everything became code, even the things that were very clearly not code.
This is the part where the system started feeling wrong to me. Not broken, but wrong in the same way a room feels wrong when everything is technically there but nothing is in its place. The bed is in the kitchen, the utensils are in the cupboard with clothes and then every morning you spend 20 minutes just remembering where you put basic things. This is what large flow config files had become. You could still work with them, but the structure was not teaching you the structure anymore.
The Old Shape
The older flow files were mostly a long list of node builders. Something like this:
def create_opening_node(prompt_data, session, exotel_sid):
starter_line = get_starter_line(prompt_data)
return {
"name": "opening",
"pre_actions": [
{"type": "tts_say", "text": starter_line},
],
"task_messages": [
{
"role": "system",
"content": build_opening_prompt(prompt_data),
}
],
"functions": [
create_confirm_identity_func(prompt_data, session, exotel_sid),
create_proceed_to_handoff_func(prompt_data, session, exotel_sid),
create_switch_language_func(prompt_data, session, exotel_sid),
create_end_call_func(prompt_data, session, exotel_sid),
],
"respond_immediately": True,
"context_strategy": append_context_strategy(),
}
This is not bad code. It is actually a very natural first version. But the issue is that after a while this function is not alone. There is opening, identity handoff, discovery, negotiation, callback scheduling, focused clarification nodes, closing nodes, final goodbye nodes, voicemail nodes and then special variants of all of these things. Then each of these nodes has different functions available in them. Then each function has a schema. Then each schema has a description. Then each handler returns another node. Then the graph exists, but the graph is not a real object, the graph is implicit in all the handler return statements.
At that point to answer a very basic question like “from this phase where can the agent go next?” you have to grep the codebase and reconstruct the graph in your head. This is usually a smell. If the thing you are building is fundamentally a graph and there is no graph file anywhere, then the codebase is hiding the most important object from you.
The same was true for prompts. The prompt is the main behavioral surface of the voice agent, but it was sitting inside python builder functions. This means that reviewing the agent meant reviewing python. And this is a weird coupling because the person reviewing whether the phase instruction is correct should not have to care about how pipecat wants its node dictionary to be shaped.
So the thought was very simple: we should stop pretending that a flow definition is code.
The New Shape
The key idea behind the migration to dock-spring was to separate definition from creation.
Definition means:
- what phases exist
- what prompt each phase has
- what functions are available in each phase
- what the function schemas are
- what the graph is
- what starter lines / voicemail / language switch phrases exist
- what knobs the runtime needs
Creation means:
- take all of this data
- validate it
- render prompts
- build pipecat function schemas
- attach python handlers
- return the exact node dict that pipecat-flows expects
Behavior means:
- async handlers
- redis/webhook/session side effects
- phone matching
- date caps
- language switching
- transcript inspection
- anything where YAML would become cursed very quickly
This became the entire design rule:
YAML/Markdown owns definition.
The DSL runtime owns creation.
Python owns behavior.
This is the part which made the whole thing click for me. We are not trying to make python disappear. That would be dumb. Python is very good at behavior. But python is not the best place to write a phase graph or a 100 line prompt or a table of language phrases. Those things deserve to be data.
So a flow in dock-spring now looks more like this:
src/services/flows/example/
flow.yaml
functions.yaml
graph.yaml
tts.yaml
prompts/
role.md
phases/
opening.md
discovery.md
callback_scheduling.md
closing.md
example_render.py
example_handlers.py
example_flow_impl.py
example_outbound_flows_config.py
Already this is much better. Without opening any python I can see that this thing has a flow manifest, functions, graph, tts copy and prompts. The shape of the directory matches the shape of the concept.
The Runtime Architecture
At a high level the system looks like this:
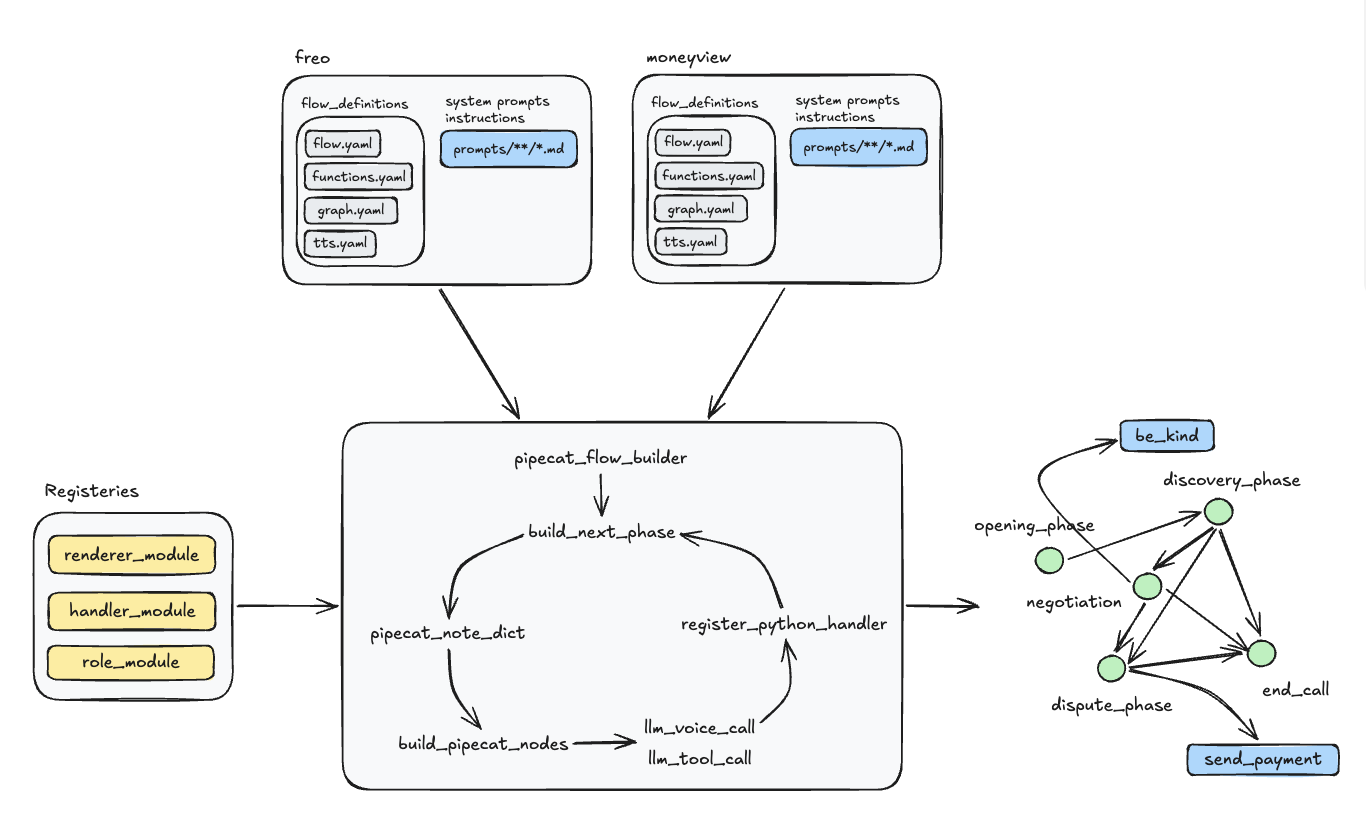
The important part is the loop at the bottom. The runtime does not only build the first node. When a handler wants to transition to another phase, it also asks the runtime to build that phase by name. This is very important because otherwise you end up with a half-migrated system where the first node comes from YAML and the next node comes from some old imperative python builder. Then you have two sources of truth and nothing good happens after that.
flow.yaml
The main file is flow.yaml. This is the file which tells you what the agent is.
flow_name: example_outbound
entry_phase: opening
runtime_extension:
- src.services.flows.example.example_render
- src.services.flows.example.example_handlers
role_prompt: prompts/role.md
supported_languages:
- en
- hi
functions_file: functions.yaml
tts_file: tts.yaml
graph_file: graph.yaml
max_phone_verification_attempts: 3
hard_end_fallback_secs: 6.0
phases:
opening:
render: opening
role: base
respond_immediately: true
context_strategy: append
pre_actions:
- type: tts_say
text_source: starter_line
functions:
- confirm_identity
- proceed_to_identity_handoff
- switch_language
- end_call
discovery:
render: discovery
role: base
respond_immediately: true
context_strategy: append
functions:
- proceed_to_callback_scheduling
- proceed_to_closing
- switch_language
- end_call
callback_scheduling:
render: callback_scheduling
role: base
respond_immediately: true
context_strategy: append
functions:
- schedule_callback
- proceed_to_closing
- switch_language
- end_call
This is so much more readable than the python version because it is only trying to answer one question: what is the flow made of? It is not trying to be clever. It is not doing side effects. It is not hiding graph edges inside closures. It is just saying that opening has these functions, discovery has these functions, callback scheduling has these functions.
I think good abstractions often have this property where they make the obvious thing obvious again. This is not some insane compiler technology. It is just taking the thing that already existed in our head and putting it in a file.
functions.yaml
The next file is functions.yaml. This is where the LLM tool interface lives.
proceed_to_callback_scheduling:
name: proceed_to_callback_scheduling
description: Move to callback scheduling when the user explicitly asks for a callback or says they are busy right now.
properties:
reason:
type: string
description: Short explanation of why callback scheduling is needed.
callback_timing:
type: string
enum:
- same_day
- later_this_week
- next_week
- unspecified
description: Best normalized timing category from the latest user turn.
required:
- reason
- callback_timing
handler:
type: proceed_to_callback_scheduling
end_call:
name: end_call
description: End the call with a short farewell only when the current phase allows it.
properties:
reason:
type: string
enum:
- resolved
- wrong_party
- voicemail
- no_response_timeout
farewell_line:
type: string
description: The line which the runtime should speak before ending the call.
required:
- reason
- farewell_line
handler:
type: end_call
This is a very important file because tool descriptions are secretly prompts. The model reads these descriptions and decides when to call the tool. So the descriptions need to be reviewed like prompts, not like boring config. Keeping them in YAML makes the diff much more honest. If the model behavior changed because a function description changed, you can actually see it.
The handler.type is the bridge back into python. The schema is declarative, but the thing that happens after the tool is called is still python.
Prompts in Markdown
Prompts live as Markdown. This sounds obvious but it matters a lot. A prompt should feel like a prompt file. It should not feel like a string inside python with indentation anxiety.
ACTIVE NODE: opening
JOB: identify whether the speaker is the expected customer without disclosing private details.
Starter already spoken: "{starter_line}" Do not repeat it.
Expected customer: {customer_name}.
ROUTING:
- If the speaker confirms identity, call confirm_identity with no assistant text.
- If this is a wrong number, apologize briefly and call end_call.
- If they ask to speak later, call proceed_to_callback_scheduling.
- If they request another language, call switch_language.
Today is {today_day}, {today_date}.
This also makes prompt iteration much nicer. You can open prompts/phases/opening.md, edit the instruction and run parity or smoke tests. You do not have to touch node construction. You do not have to think about FlowsFunctionSchema. You are just editing the agent’s instruction surface.
The role prompt is also Markdown:
You are a calm voice AI agent speaking on a phone call.
Rules:
- Keep responses short because this is live audio.
- Ask one question at a time.
- Never mention internal phase names or function names.
- If a function should be called, call it silently instead of narrating your plan.
This is the kind of separation that compounds. The first time you do it, it feels like just moving strings around. But after a few flows, it becomes the difference between a system you can reason about and a system where every change begins with “wait where is this prompt even coming from?”
graph.yaml
The graph is also data now.
phase_graph:
opening:
- identity_handoff
- discovery
- ended
identity_handoff:
- discovery
- ended
discovery:
- callback_scheduling
- closing
- ended
callback_scheduling:
- closing
- ended
closing:
- ended
dynamic_var_keys:
- customer_name
- today_date
- today_day
- starter_line
I think this is one of the biggest wins because now the graph is a real thing. It can be rendered. It can be validated. It can be compared. It can be used in tests. Earlier the graph was distributed across handlers and this made it very hard to look at the system from above.
Once the graph is a file, you can ask useful questions:
- are there unreachable phases?
- are there phases that can end too early?
- are there transitions in handlers that are not declared in the graph?
- did this PR accidentally make a dangerous edge possible?
This is the kind of thing that becomes possible only after the system is represented in the right format.
tts.yaml
The spoken fixed text also moved out.
starter_lines:
en: Hello, may I speak with {customer_name}, please?
hi: Namaste, kya main {customer_name} se baat kar raha hoon?
voicemail_messages:
en: Hi, I was trying to reach you. Please call me back when convenient. Thank you.
hi: Namaste, main aapse baat karne ki koshish kar raha tha. Kripya convenient ho to mujhe wapas call karein.
switch_phrases:
en: Sure, let me switch back to English.
hi: Theek hai, main aapke saath Hindi mein baat karta hoon.
This seems small but it prevents a lot of weird drift. Voice agents have these little pieces of fixed text which are not always part of the LLM prompt. Starter lines, voicemail, language switching acknowledgements, final fallback lines. If they live inside handler code they become easy to forget during a port. Moving them to tts.yaml makes them part of the flow definition.
The Runtime
The runtime itself is intentionally boring. It loads the YAML, validates references, imports the runtime extensions, reads Markdown prompt files and builds the node.
The core function is basically this:
def create_node(
self,
phase_name,
prompt_data,
session,
exotel_sid,
*,
include_role_message=None,
**extra,
):
phase = self._phase(phase_name)
render = get_render_builder(phase.get("render") or phase_name)
node = {
"name": phase.get("name") or phase_name,
"pre_actions": self._pre_actions(phase, prompt_data),
"task_messages": render(
self,
prompt_data,
phase_name=phase_name,
**extra,
),
"functions": [
self._build_function(fn_name, prompt_data, session, exotel_sid)
for fn_name in phase.get("functions") or []
],
}
if "respond_immediately" in phase:
node["respond_immediately"] = phase["respond_immediately"]
if phase.get("context_strategy") == "append":
node["context_strategy"] = append_context_strategy()
if include_role_message:
role_builder = get_role_builder(phase.get("role") or "base")
node["role_message"] = role_builder(self, prompt_data)
return node
There is nothing magical here and that is the point. The runtime should not be smart in a tenant-specific way. It should not know what callback scheduling means. It should not know what identity handoff means. It should only know how to take a phase definition and build the correct pipecat node out of it.
The tenant-specific things are registered.
HANDLER_BUILDERS = {}
RENDER_BUILDERS = {}
ROLE_BUILDERS = {}
def register_handler_type(name, builder):
HANDLER_BUILDERS[name] = builder
def register_render_type(name, builder):
RENDER_BUILDERS[name] = builder
def register_role_type(name, builder):
ROLE_BUILDERS[name] = builder
When the runtime imports example_render.py, it registers render functions. When it imports example_handlers.py, it registers handler builders. This allows the runtime to stay generic while the flow still has custom behavior.
Python Still Owns Behavior
This is the part where I think it would have been very easy to make the wrong abstraction. We could have tried to move everything into YAML. That would have looked very elegant for two days and then become an unreadable mess.
The correct boundary is that YAML should not become a programming language. The moment you need real logic, use python. For example:
def _schedule_callback(runtime, prompt_data, session, exotel_sid, **_cfg):
return _schema_handler(
impl._create_schedule_callback_func(
session,
exotel_sid,
prompt_data,
)
)
register_handler_type("schedule_callback", _schedule_callback)
The YAML tells the runtime that schedule_callback is available in a phase and that it maps to handler type schedule_callback. But the actual scheduling logic, the async closure, the session update, the side effects, all of that stays in python where it belongs.
The main trick we needed was for transitions. A handler should be able to say “go to this phase” without importing an old imperative node builder.
So the flow impl has this tiny node factory indirection:
_NODE_FACTORY = None
def _set_node_factory(factory):
global _NODE_FACTORY
_NODE_FACTORY = factory
def build_phase_node(phase, prompt_data, session, exotel_sid, **extra):
if _NODE_FACTORY is None:
raise RuntimeError("node factory not registered")
return _NODE_FACTORY(
phase,
prompt_data,
session,
exotel_sid,
**extra,
)
And the runtime extension wires it:
def register_runtime(runtime):
impl._set_node_factory(runtime.create_node)
This little thing is very important. It means that transition handlers build the next node through the DSL runtime. So if the handler decides to move to callback_scheduling, it does not call create_callback_scheduling_node. It calls:
return build_phase_node(
"callback_scheduling",
prompt_data,
session,
exotel_sid,
)
Now the phase definition has only one source of truth.
Keeping the Old API
Another thing that made the migration practical was keeping the old API alive. The rest of the codebase already knew how to call create_opening_node(...), so the DSL adapter exports the same function names and delegates to the runtime.
from pathlib import Path
from src.services.flows.dsl.runtime import load_dsl_flow_runtime
_FLOW_YAML_PATH = Path(__file__).with_name("flow.yaml")
_RUNTIME = load_dsl_flow_runtime(_FLOW_YAML_PATH)
_NODE_EXPORTS = {
"create_opening_node": "opening",
"create_discovery_node": "discovery",
"create_callback_scheduling_node": "callback_scheduling",
"create_closing_node": "closing",
}
def __getattr__(name):
if name not in _NODE_EXPORTS:
raise AttributeError(name)
phase_name = _NODE_EXPORTS[name]
def create_node(prompt_data, session, exotel_sid, *, include_role_message=None):
return _RUNTIME.create_node(
phase_name,
prompt_data or {},
session,
exotel_sid,
include_role_message=include_role_message,
)
return create_node
This is how you do migrations without making the rest of the system pay the price all at once. Outside the flow package nothing has to know that the node is now coming from YAML and Markdown. This let us port incrementally and prove the behavior before deleting the old builders.
Building a Tiny Agent
If we were building a tiny voice agent with this runtime from scratch, the first version could be very small.
simple_agent/
flow.yaml
functions.yaml
graph.yaml
tts.yaml
prompts/role.md
prompts/phases/opening.md
prompts/phases/booking.md
prompts/phases/closing.md
simple_render.py
simple_handlers.py
simple_outbound_flows_config.py
The flow:
flow_name: simple_booking_agent
entry_phase: opening
runtime_extension:
- src.services.flows.simple_agent.simple_render
- src.services.flows.simple_agent.simple_handlers
role_prompt: prompts/role.md
functions_file: functions.yaml
tts_file: tts.yaml
graph_file: graph.yaml
phases:
opening:
render: phase_md
prompt: prompts/phases/opening.md
role: base
respond_immediately: true
pre_actions:
- type: tts_say
text_source: starter_line
functions:
- proceed_to_booking
- end_call
booking:
render: phase_md
prompt: prompts/phases/booking.md
role: base
respond_immediately: true
functions:
- save_booking
- end_call
closing:
render: phase_md
prompt: prompts/phases/closing.md
role: base
respond_immediately: true
functions:
- end_call
The graph:
phase_graph:
opening:
- booking
- ended
booking:
- closing
- ended
closing:
- ended
The prompt:
ACTIVE NODE: booking
JOB: collect the appointment date and time.
Ask one missing field at a time.
If both date and time are present, call save_booking.
If the user asks for unavailable information, say you will note the preference.
The render function can be generic:
def render_phase_md(runtime, prompt_data, *, phase_name, **_extra):
phase = runtime._phase(phase_name)
body = runtime.prompt_text(phase["prompt"])
dynamic = prompt_data.get("dynamic_variables", {})
content = format_prompt(body, **dynamic)
return [{"role": "system", "content": content}]
register_render_type("phase_md", render_phase_md)
At this point you have a voice agent whose structure is completely visible. You can see the phases, the graph, the tools and the prompts without reading node construction code. And if tomorrow you want to add a reschedule phase, it is obvious where that change should go.
Migration From spring-agent to dock-spring
The migration process was basically:
- Take the old
spring-agentflow as the frozen reference - Extract prompts into Markdown
- Extract function schemas into
functions.yaml - Extract the graph into
graph.yaml - Extract fixed spoken text into
tts.yaml - Register the python renderers and handlers
- Build nodes only through the DSL runtime
- Prove that the new output matches the old output
- Delete the duplicate imperative builders once parity is green
The important word here is prove. It is very tempting to do this kind of refactor and then say “yeah it is the same behavior mostly”. But voice agents are too sensitive for this. A small change in function description can change when the model calls a tool. A small change in respond_immediately can change whether the agent speaks at the right time. A missing language phrase can show up only when a real call hits that path.
So we built parity tests around node fingerprints.
def node_fingerprint(node):
return {
"name": node["name"],
"task_messages": node.get("task_messages", []),
"functions": [
{
"name": fn.name,
"description": fn.description,
"properties": fn.properties,
"required": fn.required,
}
for fn in node.get("functions", [])
],
"pre_actions": node.get("pre_actions", []),
"respond_immediately": node.get("respond_immediately"),
"context_strategy": node.get("context_strategy"),
"role_message": node.get("role_message"),
}
The old imperative module and the new DSL adapter both expose create_*_node functions. So the same harness can call both, normalize the result and diff the JSON. This catches prompt drift, schema drift, function ordering drift, node flag drift and role message drift.
But not everything appears in a node fingerprint. Voicemail messages and language switch phrases can be spoken by handlers, not embedded in task_messages. So we also need direct data-layer diffs for tts.yaml, graph and knobs. And for helper behavior like phone matching, date caps or amount parsing, we need behavior batteries where the same inputs are run through both implementations.
This was a very useful lesson. The DSL is not enough by itself. The DSL plus parity harness is the actual migration system.
What It Changed
The biggest change is that flows are now easier to reason about. Earlier if I wanted to understand a flow I had to read python code and mentally separate prompt from schema from handler from graph. Now I can read the artifacts in the same form as the concept:
flow.yaml -> phase structure
functions.yaml -> tool surface
graph.yaml -> allowed transitions
tts.yaml -> fixed spoken copy
prompts/*.md -> phase instructions
handlers.py -> behavior
This is very important because most bugs in these systems are not “python syntax is wrong” bugs. They are semantic bugs. The agent repeated itself. The agent moved too early. The agent called a tool without enough information. The agent ended the call when it should have asked one more question. These bugs live at the boundary of prompt, graph, function schema and handler behavior. So the system needs to make that boundary visible.
It also changes the review process. If someone changes a prompt, I can review a Markdown diff. If someone changes a tool description, I can review a YAML diff. If someone changes a transition, I can review graph.yaml. This sounds small but these small changes compound into a much better engineering loop.
The other big impact is that dock-spring can now become the canonical home for these flows. spring-agent becomes the frozen reference which we port from and compare against, not the place where all future flow complexity keeps accumulating. This matters because every new imperative flow would otherwise increase the future migration cost.
Future
There is a lot more that becomes possible now. Since the graph is data, we can render it automatically. Since prompts are Markdown, we can build prompt review tools. Since function schemas are YAML, we can diff tool surfaces across flows. Since node construction is generic, we can build synthetic call tests that run across many tenants in the same way.
I also think there should eventually be a small authoring workbench around this. Something where you can open a flow, see the graph, click a phase, edit the prompt, run a synthetic call and see exactly which node was built and which function was called. That becomes much easier once the flow definition is not trapped inside python.
But even without that, the migration has already made the system feel much more sane. The voice agent is no longer a giant python file pretending to be a config. It is a set of phases, prompts, functions, transitions and behavior hooks. The runtime compiles it into pipecat nodes. The parity harness makes sure we did not accidentally change the agent while moving it.
This is the whole thing. Take the implicit structure that was hiding in code and make it explicit. Once that happens, the system becomes easier to understand, easier to test and much easier to evolve.